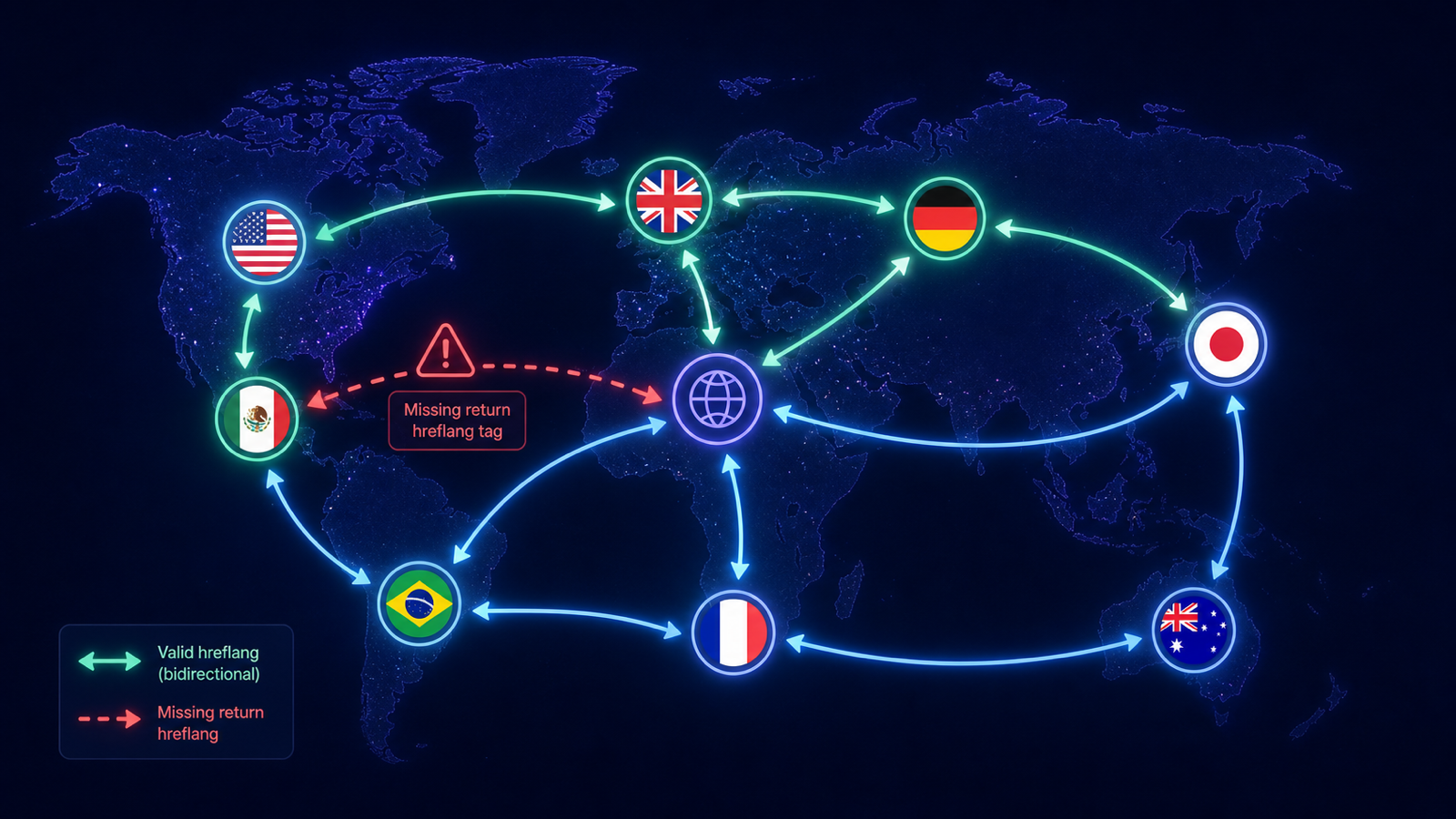
Hreflang is the SEO feature with the highest shipped-wrong rate.
Google itself has called it "one of the most complex aspects of SEO".
One missing return tag breaks the entire cluster.
One wrong language code — en-uk instead of en-gb — silently disables localization for an entire market.
Step 1. Crawl extracting every hreflang signal
The 2-UA parser captures every <link rel="alternate" hreflang> tag, including those in HTTP headers and sitemap entries.
All three sources are normalized into one cluster view per URL.
Step 2. Six hreflang errors to filter
- Missing self-reference — every page must include its own language in the cluster.
- Missing return tag — if A points to B with
hreflang="fr", B must point back to A withhreflang="en". - Invalid language code — ISO 639-1 + ISO 3166-1 only (
en-gb, noten-uk). - Conflicting canonical —
hreflang="es"pointing to a URL whose canonical points elsewhere. - Mixing hreflang sources — same cluster declared partially in HTML, partially in the sitemap.
- Pointing to non-200 URLs — broken hreflang targets break the entire cluster's trust.
Step 3. Build a return-tag matrix
Export hreflang relationships to XLSX. Use a pivot table to confirm every language pair is bidirectional. A 6-language site needs 30 directional return tags; missing one breaks the cluster Google computes.
Step 4. Add x-default
For your homepage and language-pickers, include hreflang="x-default"
pointing to your language-selector page or default-locale homepage.
Without x-default, users in unmapped locales see a poorly-matched localized URL in search results.
Patterns to avoid in 2026
- Region without language —
hreflang="us"is invalid; it must been-us. - Localizing on subdomain vs subdirectory mid-flight — pick one structure and stick to it.
- CDN serving the wrong cluster per geo — verify via VPN or curl with locale headers.
- Mixing HTML and sitemap hreflang within one cluster — Google may pick either; consistency wins.
Sitemap vs HTML hreflang
For small sites with under 500 localized URLs, declare hreflang inline in HTML. For larger sites, manage hreflang in sitemap files — they are easier to update programmatically and easier to audit. Do not mix sources within one cluster; pick one declaration style per language family.
Use the free SEO page audit for a single localized URL's hreflang check, or run a project crawl to validate your entire international tree.
Stop losing SEO performance to silent changes
If this workflow matches your current SEO bottleneck, do not postpone implementation. Teams usually lose the most traffic between detection and action, not between action and resolution. Start monitoring today and create your first baseline in under an hour.
Execution blueprint for hreflang audit
Long-form SEO implementation fails when teams try to “fix everything” at once. The sustainable approach is to define a narrow execution lane, prove measurable movement, and scale based on validated impact. For indexation workflows, this usually means setting explicit ownership, reporting cadence, and escalation thresholds.
A useful way to operationalize this is to split work into three layers: detection, validation, and rollout. Detection finds anomalies quickly. Validation confirms whether the anomaly is material or incidental. Rollout converts validated findings into engineering and content tasks with deadlines. If one layer is missing, the process becomes either noisy or slow.
90-day rollout plan
Days 1-14: baseline and instrumentation
- Define the monitored scope: templates, critical URLs, and ownership groups.
- Set expected behavior for status codes, redirects, and indexation-relevant rules.
- Enable alerts in your team channel and set an initial noise-control policy.
- Run the first full crawl and preserve it as a technical baseline snapshot.
- Document the current known issues so future alerts can be triaged faster.
Days 15-45: controlled improvement
- Move from URL-level fixes to issue-family fixes (template/system level).
- Review trends weekly for response time, quality checks, and crawl findings.
- Introduce tag-based segmentation if your team supports multiple page clusters.
- Track fix validation in re-crawls and keep a short evidence log for each change.
- Escalate only high-impact regressions to engineering to avoid context switching overload.
Days 46-90: scale and commercialization
- Standardize recurring reports for stakeholders and client-facing communication.
- Harden your alert policy with quieter thresholds and clear severity levels.
- Expand monitoring from critical templates to full coverage where justified.
- Turn recurring findings into preventive engineering tasks, not one-off tickets.
- Connect technical trend movement to revenue-adjacent metrics for executive buy-in.
Measurement model: what to track weekly
You should define a compact KPI stack that reflects both technical quality and operational speed. Over-measuring creates reporting overhead and weakens decision quality. A practical KPI model for this topic includes:
- Detection speed: time from change occurrence to first alert.
- Triage speed: time from alert to issue classification and owner assignment.
- Resolution speed: time from assignment to verified fix.
- Regression rate: how often a fixed issue class returns within 30 days.
- Coverage quality: share of critical pages included in active monitoring.
- Business relevance: proportion of high-impact issues in total issue volume.
For mature teams, the strongest KPI is not total issue count but high-impact issue recurrence. When recurrence falls, process quality is improving.
Stakeholder alignment framework
Technical SEO execution usually fails at the handoff boundary. SEO specialists detect issues, but engineering sees isolated tasks without business context. Fix this by sending implementation-ready summaries:
- What changed (objective signal, not interpretation).
- Where it changed (template, segment, or specific URL class).
- Why it matters (indexation, visibility, trust, conversion risk).
- What to do next (single recommended action with acceptance criteria).
- How to verify (which re-check confirms the fix).
If your company runs weekly planning, summarize this in one page before sprint grooming. If you run continuous delivery, post a compact incident card into Slack or ticketing with direct links.
Common failure patterns and how to avoid them
- Too much scope: teams monitor everything and fix nothing. Start with critical assets.
- No baseline: every alert feels urgent without a reference snapshot.
- Tool-only mindset: dashboards do not create outcomes without process ownership.
- One-channel reporting: executives and implementers need different output layers.
- No post-fix validation: “done” without re-check creates hidden regressions.
Operational checklist you can reuse
- Confirm scope and ownership for monitored entities.
- Establish expected behavior and escalation policy.
- Launch baseline checks and preserve initial state.
- Run weekly issue-family review with implementation owners.
- Validate completed fixes with scheduled re-checks.
- Report only high-signal movements to leadership.
- Iterate thresholds every 2-4 weeks based on false-positive rate.
Commercial impact: turning technical work into revenue protection
Teams buy monitoring platforms when they can prove one thing: technical signals reduce preventable loss and shorten recovery time. In practice, you can demonstrate this by documenting incidents prevented, recovery cycles reduced, and implementation throughput improved.
This is where aggressive execution beats passive auditing: instead of producing occasional reports, you build an operating system for technical SEO quality. Once that system is in place, scaling to more URLs, more sites, and more stakeholders becomes predictable.
Advanced FAQ for hreflang audit
How much historical data is enough for reliable decisions?
For most SEO teams, 4 to 8 weeks of consistent monitoring is enough to separate random fluctuation from structural movement. If your release velocity is high, use shorter review cycles but keep a rolling 8-week reference window. The key is consistency: gaps in monitoring reduce interpretability more than imperfect metrics.
Should we optimize for issue count reduction or impact reduction?
Always optimize for impact reduction. Lower issue count can be misleading if high-severity classes remain unresolved. In mature workflows, teams track high-impact recurrence, time-to-resolution, and incident spread by template class.
What is the best cadence for reporting this topic to leadership?
Weekly operational review plus a monthly executive summary works best. Weekly reports should focus on changes, actions, and blockers. Monthly reports should focus on trend direction, prevented incidents, and business-risk reduction. This two-layer model avoids both over-reporting and under-reporting.
How do we keep collaboration smooth with engineering teams?
Convert every finding into an implementation-ready task: define affected scope, expected behavior, acceptance criteria, and verification method. Engineering teams respond faster when tasks are deterministic. Avoid sending raw issue exports without business context.
When should we escalate from soft monitoring to stricter controls?
Escalate when any of the following is true: critical template regressions appear repeatedly, recovery time is increasing, or ownership is unclear across incidents. At that point, tighten alert policy, enforce scope ownership, and add stricter verification gates after releases.
How do we evaluate ROI for this workflow?
ROI appears in three layers: lower incident duration, fewer recurring regressions, and improved implementation confidence across teams. For stakeholder communication, quantify prevented loss events and reduced recovery effort rather than raw technical counts. This framing translates technical monitoring into business language that supports budget decisions.