How to crawl an entire website
- Open your website project and go to the Crawls page.
- In the top-right corner, click Create crawl job.
- The form shows how many crawl URLs are available for your current plan.
- In Name, enter a clear crawl job title. You can also add a private comment for your team.
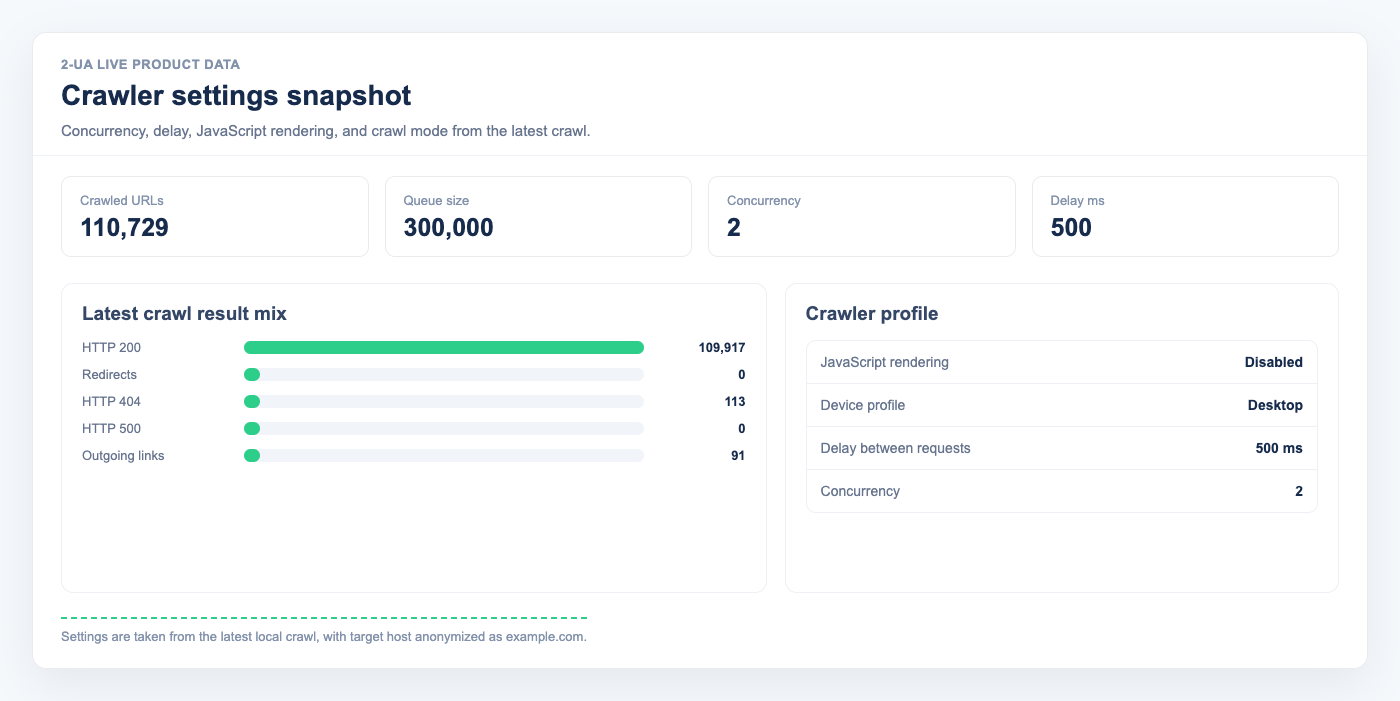
- Enable Execute JavaScript if your content is rendered client-side (SPA/JS-heavy pages). You can choose Desktop or Mobile rendering. Desktop viewport = 1920x940, Mobile viewport = 390x844.
- Set Concurrency to the number of parallel requests your website can safely handle.
- Set Delay between requests to control crawl pace. Example: with Concurrency = 1 and Delay = 200, the crawler waits 0.2 seconds between requests.
Mode
- Spider. Default mode. The crawler starts from the homepage and follows internal links like a search engine bot.
-
List. Crawl only the exact URLs you provide (paste a list or upload a file).
Note: In this mode, no additional URLs are discovered.
-
Sitemap.
Provide a sitemap URL or upload a sitemap file.
Note: The crawler will process only URLs listed in that sitemap.
Robots.txt
- Leave Specific robots.txt content empty to use your live robots.txt rules.
-
Fill Specific robots.txt content to override robots.txt for this crawl job.
Note: Custom rules replace live robots.txt rules for this run; they are not merged.
- Enable Ignore robots.txt rules to crawl without robots restrictions.
-
Enable Accept rel nofollow links to follow links marked with
rel="nofollow"(unless blocked by robots rules).
Subdomains as part of the website
- By default, crawling is limited to the current host. Enable Subdomains as part of the website if you want one crawl to include subdomains.
Other settings
-
In Response headers, add extra HTTP headers for crawl requests. They are combined with headers configured in website settings.
Note: Setting your own
User-Agentvalue here does not change how robots rules are interpreted. - In HTML body parseable mimetypes|contentTypes, define which content types should be parsed as HTML.
- In Ignore URLs ending with, list file endings or suffixes you want to skip (for example image formats).
- In Ignore URLs containing, add query fragments or path fragments that should be excluded.
-
In Ignore path, exclude whole site sections (for example
/images/or/admin/).
Note: Clicking Save creates the crawl job but does not start it automatically. Start it from the Crawls list.
Note: After the first run starts, only name, comment, concurrency, and delay can be edited.